10 věcí z BrightonSEO 2026, které změní váš přístup k vyhledávání
12. května 2026
Daniel Procházka
SEO Team Leader
26 minut čtení
Koncem dubna a začátkem května se Brighton znovu proměnil v centrum světového SEO. Už samotný program naznačoval, o čem bude hlavní téma. AI byla všude: v přednáškách o měření, technickém SEO, migracích, YouTube, Redditu, brandu, obsahu, entitách i automatizaci.
A přesto nebyla atmosféra apokalyptická – spíš praktická. Méně „AI zabije SEO“, více „co přesně máme od pondělí dělat jinak a v čem pokračovat“.
Největší posun? SERP už dávno není jen seznam modrých odkazů. Stává se komplexní sítí odpovědí, citací, doporučení, komunitních signálů, videí, recenzí a strukturovaných informací, ze kterých si vyhledávače a AI skládají vlastní obraz o značce.
1. Konec jednoduchého SEO modelu pozice → klik → konverze
Jedna z nejsilnějších linek celé konference byla měřitelnost.
Starý model organického vyhledávání stál na relativně jednoduché logice: zlepšíme pozice, získáme víc prokliků, přivedeme víc návštěv a z nich přijdou konverze.
Jenže AI výsledky, AI Overviews, AI asistenti a vyhledávače a odpověďové rozhraní v kombinaci se zero-click trendem tuhle přímku rozbíjejí.
Aleyda Solis (zakladatelka SEOFOMO a Orainti)ve své přednášce „Redefining Success Metrics for the AI Search Era“ popsala rozdíl velmi jasně. Tradiční vyhledávání bylo založené na stabilní pozici, klik-first chování a jednom hlavním vyhledávači. AI Search oproti tomu stojí na syntetizovaných odpovědích, nestálých výstupech, vlivu, který se často neprojeví kliknutím, a roztříštěnosti napříč různými platformami.
Jinými slovy: už nestačí měřit jen návštěvnost z organiku. AI může ovlivnit rozhodnutí uživatele, aniž by se v GA4 objevila jako návštěva.
Aleyda proto navrhla tři vrstvy metrik pro AI Search:
Presence – zda se značka vůbec objevuje v AI odpovědích a jak je reprezentovaná
Readiness – zda je strukturálně připravená být citována
Business Impact – zda se tato viditelnost promítá do obchodní hodnoty
Cílem ale není předstírat dokonalé měření původu každé konverze a spojovat ji s konkrétní AI odpovědí. Aleyda výslovně upozorňuje, že business impact model má být poctivý reportingový rámec pro plánování a prioritizaci, ne způsob, jak si uměle připsat veškerý brandový růst k AI.
Doporučuje kombinovat pozorovaná data, proxy signály (nepřímé ukazatele, že konverze/proklik byl ovlivněn AI) a modelované odhady s různou mírou důvěryhodnosti.
Mezi užitečné vstupy patří například AI referred sessions, AI conversion rate, vývoj brandového vyhledávání nebo direct traffic na citované stránky. Jako TIP k lepšímu měření zmiňuje jednoduchou otázku, kterou ve fázi registraci/nákupu či jiné konverze položit uživateli: „Narazili jste na naši značku v AI asistentovi před nákupem?“
Zdroj: Aleyda Solis, BrightonSEO 2026
Tři body, co si zapamatovat
AI referral traffic je jen minimum dopadu
Aleyda Solis říká, že návštěvnost přímo z AI nástrojů je „floor, not ceiling“, tedy spodní hranice, ne celý vliv AI. Část uživatelů značku uvidí v AI odpovědi, ale později přijde přes Google, direct nebo brandový dotaz.
Brandové signály mohou růst mimo přímé AI návštěvy
V příkladu Aleyda ukazovala také +22 % QoQ růst brandového vyhledávání a +38 % QoQ růst direct trafficu na konkrétní stránku.To naznačuje, že AI mohla ovlivnit poptávku i bez přímého kliku z AI nástroje.
AI visibility bez kontextu může klamat
Cosmin Negrescu (zakladatel a CEO SEOmonitor) v jiné prezentaci připomněl, že samotná viditelnost v AI odpovědích nestačí. Musíme vědět, jestli daný prompt reprezentuje reálnou poptávku, důležitý intent a obchodní hodnotu.
Jinak si můžeme vytvořit hezký AI visibility report, který ale nebude vysvětlovat návštěvnost, poptávku ani revenue. Pokud všechny prompty vážíme stejně, můžeme přeceňovat témata, která v praxi skoro nikdo neřeší, a naopak podcenit dotazy, které skutečně ovlivňují nákupní rozhodování.
2. AI Search není jeden kanál: ChatGPT, Google AI Mode a Perplexity se chovají jinak
Další velké téma: přestat mluvit o „AI Search“ jako o jednom prostředí. Každá platforma má vlastní zdrojový ekosystém, vlastní logiku výběru citací a vlastní slabá místa.
Tom Smeaton (SEO Manager Squarespace) prezentoval výzkum, ve kterém Squarespace spolu s Peec AI analyzoval 1,2 milionu citací napříč ChatGPT, Google AI Mode a Perplexity. Studie se zaměřila na prompty, které uživatelé vyhledávají v souvislosti s profesionálními službami ve třech vertikálách: Zdraví & Krása, Profesionální služby a Školení & Vzdělávání.
U profesionálních služeb AI nemá k dispozici produktová data ani SKU (identifikátor konkrétního produktu nebo varianty produktu) jako v e-commerce. O to víc se při doporučování opírá o reputaci, důvěryhodnost, lokální signály a srovnávací obsah.
Zdroj: Tom Smeaton, BrightonSEO 2026
ChatGPT v tomto kontextu více sahal po článcích (více než 20 % citací), Google AI Mode po sociálním obsahu (přes 90 % všech citací z Instagramu bylo v AI mode a zbylých 10% v ostatních platformách) a Perplexity po seznamových doporučeních (více než třetina všech citací byly tzv. listicles *)
* Listicles jsou články postavené jako seznamy. Typicky „nejlepší X“, „top 10 nástrojů“, „7 doporučených agentur“, „nejlepší salony v Londýně“, apod. V SEO/AI Search kontextu jde hlavně o srovnávací a doporučovací články, ze kterých si AI může snadno vzít kandidáty pro odpověď.
U služeb tedy nestačí mít jen dobře napsaný web. Značka musí být přítomná tam, kde daná AI platforma hledá „důkaz“, čili obsah, který cituje.
Zdroj: Tom Smeaton, BrightonSEO 2026
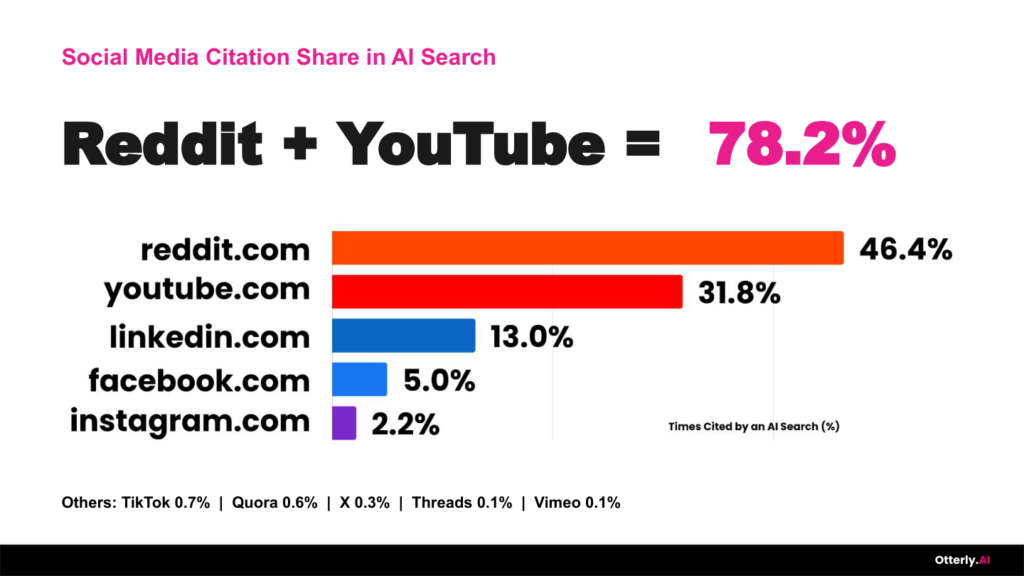
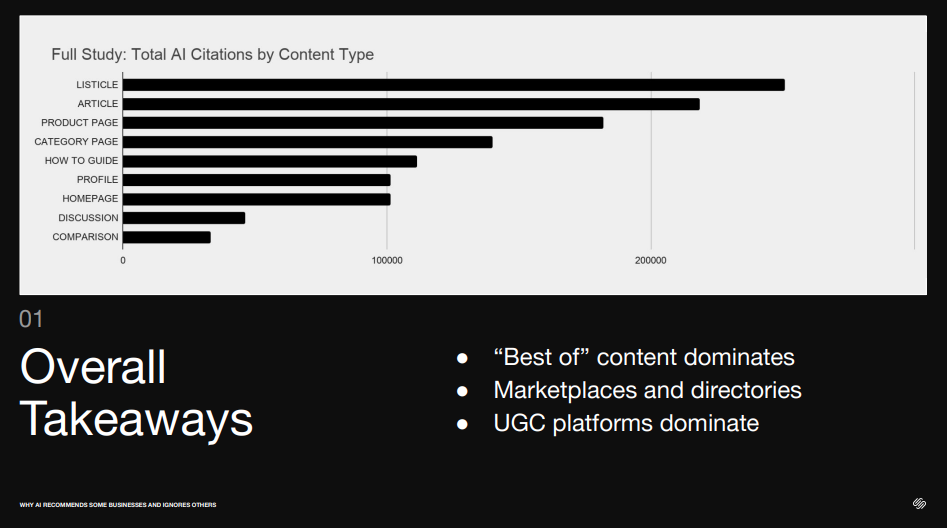
Tuhle myšlenku silně potvrzovala i přednáška Ricka Tousseyna (GEO Content Strategist OtterlyAI) o YouTube citacích v AI Search (viz níže). Jeho tým analyzoval 100 milionů AI citací napříč šesti platformami během 30 dní. Z toho 5,5 milionu citací pocházelo ze sociálních a video platforem a 1,7 milionu přímo z YouTube. Zajímavé bylo, že Reddit a YouTube dohromady tvořily 78,2 % social media citation share v AI Search.
Ještě důležitější než samotná čísla byla „platformová fragmentace“: více než 56,2 % YouTube AI citací pocházelo z Google AI Overviews a Google AI Mode. YouTube je jednoduše král v Google AI ekosystému, zatímco ChatGPT má jako nejsilnější sociální zdroj Reddit a Copilot LinkedIn, což dává smysl vzhledem k Microsoft ekosystému.
Tomův rámec pro viditelnost v AI vyhledávání u služeb stál na třech krocích:
prosadit se ve fázi objevování,
získat zmínky ve srovnáních a na sociálních platformách
a mít web s kvalitním, jasně strukturovaným obsahem, který mohou AI systémy snadno citovat.
Mezi zdroje, které reálně pomáhají AI citacím u profesionálních služeb, patřily stránky oborových katalogů, Yelp (online katalog a recenzní portál pro lokální firmy a služby) a lokální profily, niche editorial listicles, Instagram Reels pro Zdraví & Krásu, Google Maps jako základ a zároveň varování před tím, že spoléhat se jen na obecnou stránku „Services / Služby” nestačí.
Tohle je zvláště důležité pro malé a střední firmy. Dříve stačilo řešit „máme dobrý web?“ Dnes je přesnější otázka: „má AI dost nezávislých důkazů, aby nás mohla doporučit?“
Daniel Procházka, SEO Team Leader
3. Technické SEO nezmizelo, jen se rozšířilo o AI crawlery, web fetch a agentní přístup
Kdo čekal, že v roce 2026 technické SEO ustoupí brandu a obsahu, musel z BrightonSEO odejít zklamaný. Technický základ je pořád vstupenka do hry. Jen už nejde pouze o Googlebota.
Dave Cousin (DavetheSEO), v přednášce o future-proof migracích ukázal, že web dnes musí obsloužit více typů „návštěvníků“ najednou.
Popsal čtyři front-endové toky:
uživatelé,
browser-based AI pracující s vizuálním rozhraním,
AI web fetch funkce,
budoucí standardy typu WebMCP.
Zásadní rozdíl je v tom, jak se k obsahu dostávají. Lidé si poradí s rozhraním, i když není dokonalé. Browser-based AI se pokouší interpretovat web podobně jako člověk, ale může být pomalá, tokenově drahá a může se zaseknout. AI web fetch je ještě přísnější: typicky tahá jen viditelný text ze zdrojového kódu, pokud se na stránku vůbec dostane.
Dave shrnul minimum pro AI-friendly web poměrně konkrétně:
stránky musí být viditelné ve výsledcích vyhledávání,
AI user-agent se musí dostat na URL
a klíčový obsah musí být dostupný jako viditelný text ve zdrojovém kódu.
V jeho „minimum viable product“ pro nový web se objevuje robots.txt bez blokace LLM user-agentů, bezpečnostní a CDN nastavení, která zbytečně neblokují AI crawlery, opatrnost u IP-based redirectů, paywallů, loginů, captcha ochran a human verification.
Zdroj: Dave Cousin, BrightonSEO 2026
Důležitá pointa z jeho prezentace byla i ta, že největším rizikem není migrovat příliš brzy, ale migrovat na „brittle site“, tedy web, který je křehký, špatně rozšiřitelný a nepřipravený na nové protokoly.
Pokud má nový web obsah jen přes JavaScript, nemá API přístup, nedovoluje vlastní pole ani vlastní kód, může každá další změna znamenat další přestavbu. Naopak web s obsahem ve zdroji, API ready architekturou, flexibilními poli, možností injektovat kód a rozumnou autentizací se dá na nové standardy spíš přenastavit než znovu stavět.
Jak přistupovat k webu, když migrace proběhla a výsledky jsou špatné
Jeroen Driehuis (SEO Specialist v Onder) ve své přednášce přistoupil k migracím jako k šestikrokové diagnostice. Popsal postup, který následuje, když se na něj obrátí klient po migraci webu spojenou s poklesem tržeb, trafficu či jinými problémy.
Než vůbec začne hodnotit, co se pokazilo, doporučuje zjistit kontext: proč migrace proběhla, jaké měla cíle, jaká rozhodnutí padla a jaká technická omezení projekt měl.
Zároveň upozorňuje na důležitou věc: pokles trafficu nebo visibility automaticky neznamená špatnou migraci. Nejdřív je potřeba shromáždit data z GA, GSC, backlink profilu, starých crawlů, Wayback Machine a historie SERPů.
Jeho šestikrokový přístup začíná otázkou, jestli jsou důležité stránky vůbec pořád dostupné. Poté řeší crawlability: zda user-agenti mohou vidět důležité stránky, jestli robots.txt neblokuje něco zásadního, zda interní odkazy nemají nofollow, jestli nejsou problémy v sitemapách a zda nevznikly orphan pages.
Nejdřív je hlavním cílem zjistit, co bylo před migrací důležité: stránky, dotazy, konverze, rozhodnutí a technická omezení. Poté rozebrat problém přes dostupnost, crawlability, indexovatelnost, renderovatelnost, interpretovatelnost a klikatelnost.
U renderingu upozorňoval na JavaScript dependencies, obsah závislý na interakci a rozdíly mezi raw a rendered HTML. U interpretovatelnosti zase na strukturovaná data, hierarchii nadpisů a shodu obsahu s user intentem.
Pointa je jednoduchá: AI search „nezrušil“ technické SEO. Stala se z něj nezbytnost. Pokud stránka není přístupná, čitelná, renderovatelná a srozumitelná, nedostane se ani k člověku, ani k modelu. A pokud je web postavený křehce, bez kontroly nad obsahem, API, logy, CDN a renderováním, bude čím dál těžší reagovat na nové AI rozhraní, crawlery a protokoly.
Tři důležité body, co si zapamatovat
AI bot není jen nový Googlebot
Různé AI systémy přistupují k webu jinak: některé tahají text ze zdrojového kódu, jiné se snaží interpretovat vizuální rozhraní a další budou pracovat přes protokoly a endpointy. Web proto musí být čitelný pro lidi i stroje.
Migrace není jen redirect mapa
U migrací je potřeba řešit dostupnost obsahu, crawlability, sitemapu, interní odkazy, URL strukturu, canonicaly, duplicate content, produktové clustery i platformní omezení.
Budoucnost technického SEO je flexibilita
Cílem není vsadit všechno na jeden protokol, ale být protocol-agnostic: mít obsah dostupný ve zdroji, API-ready architekturu, možnost custom polí, úpravy kódu, kontrolu nad CDN a logy.
4. Entity SEO: Z „řetězce slov“ na rozpoznatelnou věc
Jeden z největších myšlenkových posunů se týkal entit. Felipe Bazon (SEO Manager v HEDGEHOG) ve své prezentaci formuloval moderní SEO triádu: Entity Optimisation, Topical Authority a Information Gain. Podle něj samotná klíčová slova už nestačí, protože Google i AI systémy se posunuly k chápání témat, konceptů a entit.
Zdroj: Felipe Bazon, BrightonSEO 2026
Entity SEO definoval jako snižování nejednoznačnosti kolem značky tak, aby ji vyhledávače a AI systémy chápaly jako entitu, ne jen jako textový řetězec.
V praxi to znamená jasně ukázat, kdo značka je, co dělá, s jakými tématy má být spojována a jaké signály podporují její legitimitu. Felipe to shrnul jako přechod značky ze „string“ módu do „thing“ módu.
Dobře to ukázal na příkladu slova Hedgehog. Stejný výraz může znamenat zvíře, agenturu nebo kapelu. Teprve kontext, související entity, vlastnosti a vztahy určují, kterou „věc“ má systém vybrat.
Právě tady je podstata Entity SEO: nestačí, aby se název značky někde opakoval. Systém musí pochopit, o jakou entitu jde, v jakém kontextu existuje a k čemu má být přiřazena. Felipe v prezentaci zmiňuje, že Knowledge Graph čerpá mimo jiné z Wikidata a Wikipedie, licencovaných datasetů, strukturovaných dat z crawlovaných stránek a referencí z jiných autoritativních entit.
To navazuje na informace z přednášky Genie Jones (inLinkds) o AI Visibility. Jejím hlavním argumentem bylo, že AI systémy neodměňují značku za to, že na stránce opakuje správnou frázi. Potřebují, aby byla značka jasně identifikovatelná jako firma, osoba, služba, místo nebo produkt, kterému znalostní graf rozumí. Prakticky to znamená čisté schema, strukturované stránky „O nás“, konzistentní naming napříč webem a odkazy na autoritativní zdroje, kde dávají smysl.
Zajímavý praktický detail z podkladů: u schema markupu nestačí jeden izolovaný typ. U komplexnějších webů dává smysl propojovat Organization, LocalBusiness, Service, Person, FAQPage nebo BreadcrumbList pomocí @id, aby Google i AI systémy viděly vztahy mezi firmou, lidmi, službami a lokalitami jako jeden celek.
5. Topical authority už nestačí, obsah musí přinášet „information gain“
Felipe Bazon šel ještě dál. Topical authority podle něj zůstává klíčová, protože v AI Search pomáhá webu stát se důvěryhodným zdrojem v konkrétní situaci. Buduje se přes topical map, entity research značky, produktů a autorů, obsahové huby a clustery, podporující články, vlastní research, videa, social distribuci a entity link building.
Ale samotná autorita je jen pozvánka na večírek.
Aby vás systém opravdu poslouchal, potřebujete information gain, tedy unikátní základní hodnotu oproti tomu, co už na webu existuje.
Zdroj: Felipe Bazon, BrightonSEO 2026
Felipe to popisuje jako obsah, který nevrací AI její vlastní tréninková data zpět v jiné podobě, ale přináší něco, co systém ještě „neví“: vlastní data, nové úhly pohledu, unikátní zkušenosti, odlišné závěry nebo originální analýzu.
To je důležité i pro obsahovou strategii. V éře AI nestačí napsat „nejlepší průvodce tématem X“, pokud je to jen shrnutí prvních deseti výsledků. Lepší otázka zní: Co můžeme přidat, co nikdo jiný nemá?
6. Reddit a UGC: AI chce lidské odpovědi, ne firemní brožury
Reddit byl na BrightonSEO jedním z nejviditelnějších témat. Ne jako „další sociální síť“, ale jako datový zdroj pro search, AI odpovědi a brand perception.
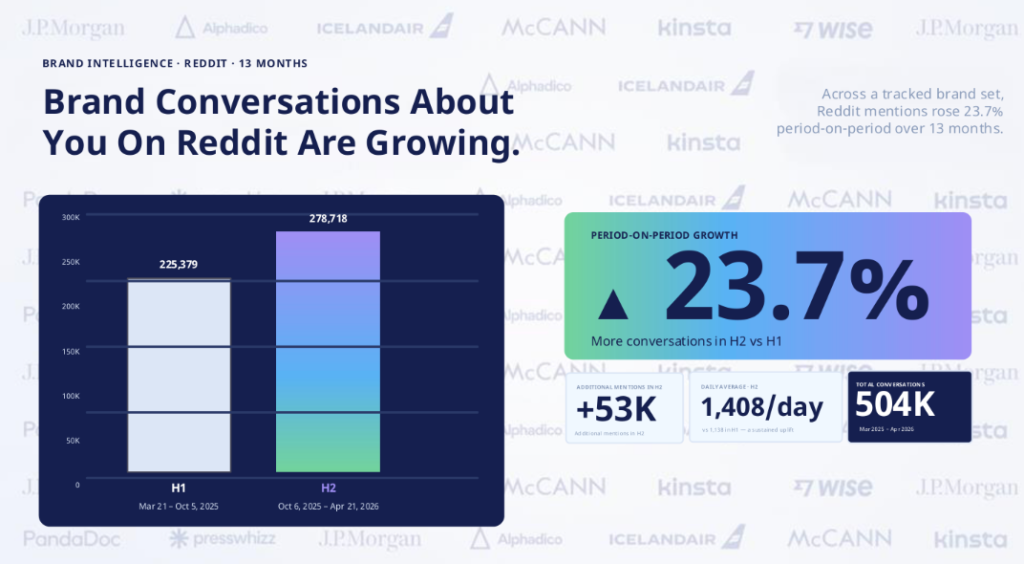
Ainhoa Lizarralde (International Head of SEO MarketFully Group) ve své prezentaci o zero-click světě ukázala, že u sledované sady značek vzrostly brandové konverzace na Redditu za 13 měsíců o 23,7 %. V datech bylo 504 tisíc konverzací mezi březnem 2025 a dubnem 2026, přičemž druhé období přidalo přes 53 tisíc zmínek navíc.
Zdroj: Ainhoa Lizarralde, BrightonSEO 2026
Ještě silnější jsou další čísla: podle prezentace mělo 73 % firem Reddit vlákna na první stránce výsledků pro brandové dotazy.
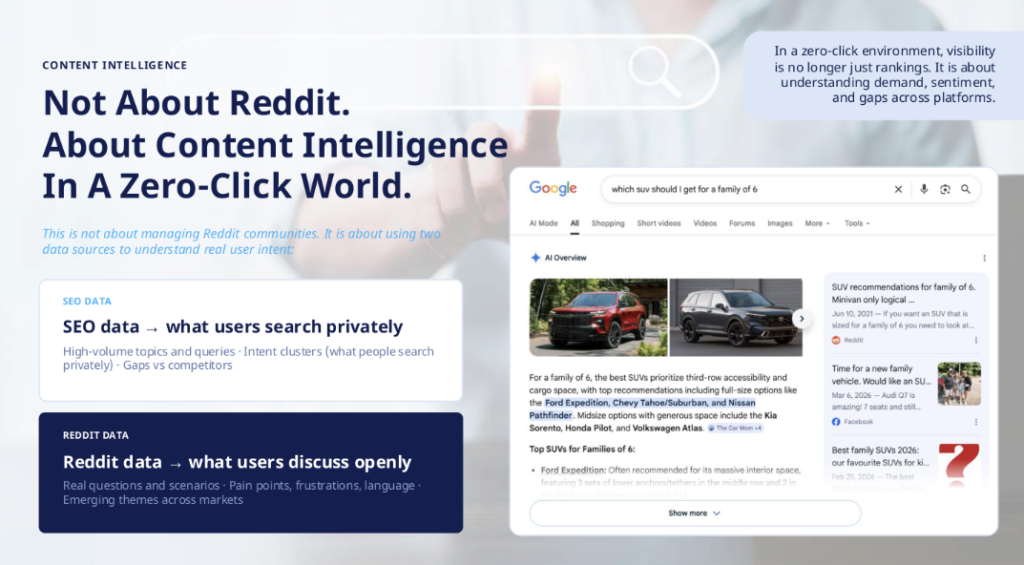
Reddit tedy není jen místo, kde si lidé povídají. Je to často veřejná vrstva reputace značky, kterou vidí Google, uživatelé i AI systémy.
Ainhoa zároveň zdůrazňovala, že pointa není „dělat Reddit strategii“ za každou cenu. Důležitější je využít Reddit jako zdroj content intelligence v zero-click světě. SEO data ukazují, co lidé hledají soukromě. Reddit data ukazují, o čem lidé mluví otevřeně: jak popisují své problémy, jaké scénáře řeší, jaké používají formulace a co je na značkách skutečně zajímá.
Zdroj: Ainhoa Lizarralde, BrightonSEO 2026
To je velký rozdíl oproti klasické analýze klíčových slov. Klíčová slova často zachytí poptávku, ale ne vždy zachytí frustrace, pochybnosti, srovnávání, kompromisy a reálný jazyk zákazníků. Reddit naopak ukazuje, jak lidé mluví, když zrovna nejsou v „search módu“, ale v konverzaci s ostatními.
Victory Umurhurhu-Michael k tomu přidala pohled na autenticitu. V její prezentaci zaznělo, že lidé chtějí odpovědi, které zní jako od lidí. Reddit proto získává význam v kombinaci AI Search, user-generated discussions, search intentu a forum výsledků. Zároveň ale upozorňovala, že Reddit není místo pro korporátní sebepropagaci. Redditoři mají vysokou bariéru důvěry, dávají tvrdou, ale autentickou zpětnou vazbu a netolerují self-promo.
V její prezentaci zazněla i zajímavá data o roli Redditu v customer journey: 71 % lidí, kteří objevili značku jinde, ji následně zkoumalo na Redditu, a 88 % uživatelů udělalo nákupní rozhodnutí na základě informací nalezených na Redditu.
7. YouTube jako citovatelný zdroj: Nevyhrává největší kanál, ale nejlepší odpověď
Velmi zajímavá byla také data Ricka Tousseyna z OtterlyAI. Jejich YouTube AI Citation Study analyzovala 100 milionů AI citací napříč šesti platformami během 30 dní. Z toho 5,5 milionu citací pocházelo ze sociálních a video platforem a 1,7 milionu z YouTube. Reddit a YouTube dohromady tvořily 78,2 % social media citation share v AI Search.
Zdroj: Rick Tousseyn, BrightonSEO 2026
YouTube je obzvlášť silný v Google ekosystému: více než 56,2 % YouTube AI citací pocházelo z Google AI Overviews a AI Mode. Rick zároveň ukázal, že 94 % AI citací mířilo na long-form videa, zatímco Shorts tvořily jen 5,7 %. Nejčastěji citovaný rozsah videí byl 5–20 minut, kam spadalo 58,2 % citovaných videí.
Největší překvapení? Popularita skoro nekorelovala s citacemi.
Počet zhlédnutí, lajků ani odběratelů neměl relevantní korelaci s citation frequency. Naopak popis videa a metadata měly slabý, ale pozitivní signál. Dokonce 40,8 % citovaných videí mělo méně než 1 000 zhlédnutí, 36 % méně než 15 lajků a 35 % citovaných kanálů méně než 10 tisíc odběratelů.
Praktický závěr? Stavte videa jako dokumentaci, ne jen jako entertainment. Dlouhodobě hodnotná vysvětlující videa, návody, porovnání, walkthroughs a případové studie s kapitolami, timestampy a metadata-rich popisem jsou pro AI citovatelnější než krátký virální obsah bez struktury.
8. Audience research před optimalizací: Nejdřív lidé, potom embeddingy
Vedle všech technických a AI témat zněla v Brightonu ještě jedna zdravá připomínka, kterou vždy rád zmíním: pořád optimalizujeme pro lidi.
Emina Demiri-Watson (Vixen Digital) ve své prezentaci „Before cosine and fan-out, there is audience“ ukázala jednoduchý, ale silný příklad. Klient měl v navigaci slovo, které interně používal celý tým, ale cílová skupina mu nerozuměla.
Po změně terminologie na jazyk publika přišel během tří týdnů 64% nárůst revenue, 567% nárůst key events a 160 nových uživatelů oproti 24 před změnou.
Emina svůj audience research nestavěla jen na analýze klíčových slov. Kombinovala několik zdrojů, které jí pomohly pochopit, jak lidé o tématu opravdu mluví, co vnímají pozitivně nebo negativně a jaké problémy se opakují napříč různými kanály.
Z recenzí na Trustpilotu vytahovala opakující se témata a sentimen, tedy jestli lidé o konkrétním problému mluví pozitivně, negativně nebo neutrálně. Pomocí Google Cloud NLP analyzovala entity, tedy konkrétní značky, produkty, funkce, místa nebo pojmy, které se v textech objevují.
Reddit používala jako zdroj přirozených diskuzí. Pomocí Reddit Topic Cruncheru a BERTopicu dokázala z většího množství vláken vytáhnout hlavní témata, která lidé spontánně řeší. A nakonec přes AlsoAsked sledovala otázky, které uživatelé pokládají ve vyhledávání.
Zdroj: Emina Demiri-Watson, BrightonSEO 2026
Cílem tedy nebylo jen vytvořit seznam dotazů pro obsahový plán. Šlo o to pochopit, jaké entity lidé zmiňují, v jakém kontextu, s jakou emocí, pod jakými tématy a kde existují mezery mezi tím, co značka komunikuje, a tím, co publikum skutečně potřebuje slyšet.
Tohle je důležitá protiváha k AI hype. Ano, můžeme (a doporučuji) řešit fan-out queries, embeddings, entity density a citation graphs. Ale pokud používáme jazyk, kterým mluví interní tým a ne zákazník, celá strategie se hroutí na první úrovni.
9. Automatizace, MCP a agentní SEO: SEO specialista jako organizátor systémů
Další výrazná linka byla automatizace. Ne ale ve smyslu „AI nám napíše 500 článků“, ale ve smyslu propojení nástrojů, dat a workflow tak, aby SEO specialista nemusel pořád dokola ručně dělat práci, kterou lze bezpečně předat systému.
Gus Pelogia (Indeed) ukázal praktické využití MCP serverů pro SEO. Model Context Protocol popsal jako open-source standard od Anthropic, který umožňuje AI modelům bezpečně se připojovat k externím nástrojům.
Zdroj: Gus Pelogia, BrightonSEO 2026
Jeho use-cases byly velmi praktické: organizace klíčových slov do skupin, čerstvé SERPy podle města, scraping SERP features, kombinování MCP nástrojů a historická data s vizualizací. Například u keyword grouping ukazoval výstup 87 klíčových slov v jedné linii, u lokálních SERPů řešil situaci, kdy potřebujete čerstvé výsledky z jiné lokality bez ručního nastavování Chromu.
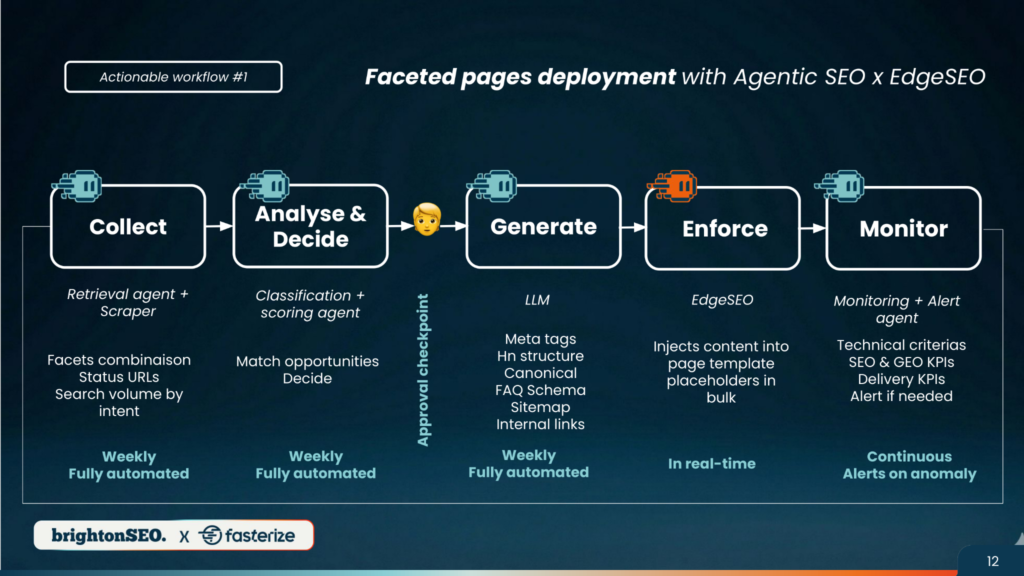
Valentine Jahan (Fasterize) zase ukázala kombinaci Agentic SEO a EdgeSEO. V jednom workflow pracovala s faceted pages: sběr dat, analýza, rozhodnutí, generování metadat, canonicalů, FAQ schema, sitemap a interních odkazů, nasazení na edge a monitoring.
V druhém workflow řešila obohacení více než 2 000 store pages pro SEO a AI Search. Výsledek prezentovaného retail příkladu: 2 000+ automaticky obohacených stránek, desetinásobek SEO kliků za čtyři měsíce, 5 000+ klíčových slov v Top 10 a citace v ChatGPT, Gemini a Claude.
Zdroj: Valentine Jahan, BrightonSEO 2026
Automatizace tedy není jen „uděláme víc textů“, jak k ní mnoho lidí přistupuje. Silnější směr je organizace: agent sbírá data, vyhodnocuje příležitosti, navrhuje změny, člověk schvaluje a edge vrstva nasazuje ve velkém.
SEO specialista se neposouvá do role člověka, který všechno ručně kontroluje a přepisuje. Posouvá se do role architekta systému: nastavuje pravidla, kontroluje kvalitu, určuje priority a rozhoduje, co se smí automatizovat a co musí zůstat pod lidským dohledem.
10. Server logy jako obsahový radar
Yvie Ansari (Head of SEO Snaptrip Group) připomněla nástroj, který se v běžných content strategiích pořád používá málo: server access logs. Ne jako jediný zdroj pravdy, ale jako doplněk k uživatelským datům.
Sama na začátku upozorňovala, že obsahová strategie nemá stát jen na zkoumání access logů — vždy musí vycházet hlavně z uživatelů a jejich chování. Logy ale pomáhají pochopit, jestli se důležitý obsah vůbec dostává před boty a jak ho různé crawlery objevují.
Její doporučení: standardně sledovat Google, ale přidat i Bing, ChatGPT, Perplexity a Claude. Protože jak určitě víme, v AI éře totiž nestačí vědět jen to, co dělá Googlebot. Důležité je vidět, jestli a jak se k obsahu dostávají i AI crawlery a další systémy, které mohou ovlivňovat viditelnost značky.
Klíčová je podle ní kategorizace. Nestačí mít jen seznam navštívených URL. Logy začnou být užitečné až ve chvíli, kdy URL rozdělíte podle site section, locale a bot. Teprve potom se dá zjistit, které obsahové clustery roboti navštěvují, které ignorují a jestli se některé části webu nedostávají mimo jejich dosah.
Zdroj: Yvie Ansari, BrightonSEO 2026
Z logů lze podle Yvie hypotetizovat a odpovědět si tak na otázky typu:
Jaký obsah je pravděpodobně výkonný?
Mají boti „rádi“ nový obsah?
Chybí na webu nějaký obsah, který boti očekávají?
Existují části webu, kam se LLM či Google vůbec nedostanou?
To je důležité hlavně u velkých webů, kde mohou být některé stránky technicky dostupné, ale prakticky téměř neobjevované.
Validace přes GA pak pomáhá pochopit, zda obsah funguje i u lidí, nejen u botů. Jinými slovy: vysoký bot access s nízkým výkonem může ukazovat na problém s kvalitou, intentem nebo E‑E-A‑T. Naopak důležitý obsah s nízkým bot accessem může být příležitost pro lepší interní prolinkování, sitemapu nebo odstranění technických překážek.
Co si z BrightonSEO 2026 odnést?
BrightonSEO 2026 podle mě ukázalo jednu hlavní věc: SEO se nerozpadá. Jen přestává být (a již nějakou dobu opravdu není) izolovanou disciplínou.
Technické SEO zůstává základem. Bez přístupného, čitelného a dobře strukturovaného webu se značka nedostane ani k vyhledávači, ani k AI crawlerům. Jenže technika dnes nekončí u Googlebota. Musíme počítat s web fetch funkcemi, různými user-agenty, renderováním, logy, strukturovanými daty a tím, jak snadno si stroje dokážou obsah vůbec přečíst.
Obsah je pořád klíčový. Ale nestačí „pokrýt klíčová slova“. Obsah musí mluvit jazykem publika, být ukotvený v entitách, přinášet vlastní data, zkušenosti nebo nový úhel pohledu a být napsaný tak, aby ho šlo citovat. Průměrné shrnutí toho, co už existuje jinde, bude v AI éře stále méně stačit.
Brand je důležitější než kdy dřív. Nejen na webu, ale v listicles, recenzích, komunitách, videích, lokálních profilech, social signálech a třetích stranách, kterým AI systémy věří. Otázka už není jen „co o sobě říkáme my“, ale „co o nás říká celý ekosystém“.
A měření se musí změnit. Kliky nezmizely, ale už nejsou jediným důkazem hodnoty. Budeme muset sledovat viditelnost, reprezentaci značky, kvalitu citací, brandový traffic i hledanost, direct traffic, dotazníky, nepřímé signály i modelovaný dopad. Ne proto, abychom si uměle připisovali zásluhy, ale abychom lépe pochopili, kde SEO skutečně ovlivňuje rozhodování.
Nejkratší shrnutí celé konference by mohlo znít takto:
SEO v roce 2026 už dávno není boj o pozice, ale boj o důvěryhodnost v ekosystému odpovědí.
A vyhraje ten, kdo bude pro lidi srozumitelný, pro vyhledávače čitelný a pro AI dostatečně ověřitelný.
Daniel Procházka, SEO Team Leader
Daniel Procházka
SEO Team Leader
Dan chtěl dělat kreativní marketing a vymýšlet kampaně. Pak ale narazil na SEO a bylo hotovo. Do světa vyhledávačů se dostal v roce 2020 přes správu e‑shopu a od té doby ho baví jak technická stránka SEO, tak práce s obsahem. Nejde mu jen o to dostat weby na přední příčky, ale taky o to, aby klienti rozuměli, proč a jak se tam dostanou. Proto na SEO nejen pracuje, ale i vysvětluje – protože když klient chápe, co se děje, mnohem líp se pak ladí strategie a celý projekt roste.


 Daniel Procházka, SEO Team Leader
Daniel Procházka, SEO Team Leader